
The RBA has an interesting article on GDP revisions in their most recent bulletin. This follows up on an awesome RDP on real time RBA forecast performance (see my prior post).
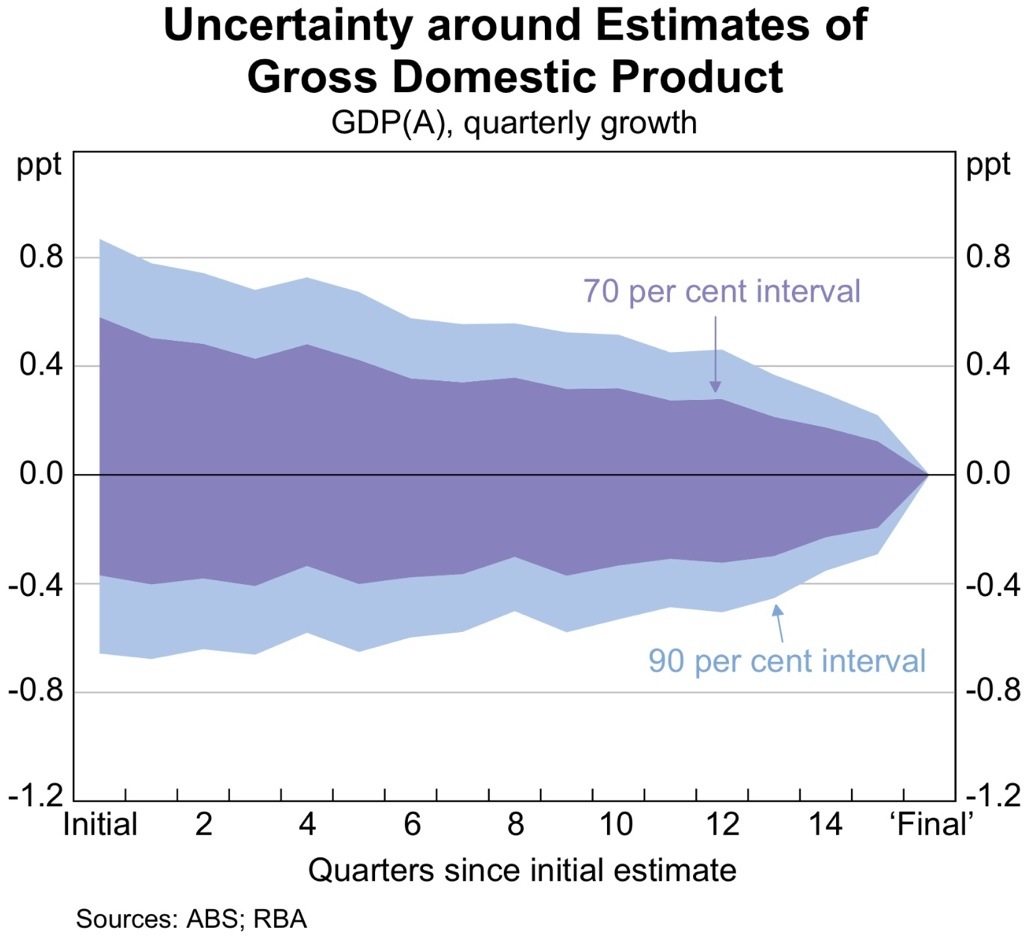
This paper deals with a key source of error when it comes to forecasting — that we often do not know where we are, or where we have been, when we are trying to gauge the outlook. The above chart shows that the one sigma confidence interval is around 100bps when a quarterly GDP print is released (so an initial 0.5%qoq result may turn out to be a -0.5%qoq result once all the revisions are in).

The above table shows that the errors are large for each component, and that the revisions go on for some time. The errors are smaller for the aggregate, as they cancel out when summed.
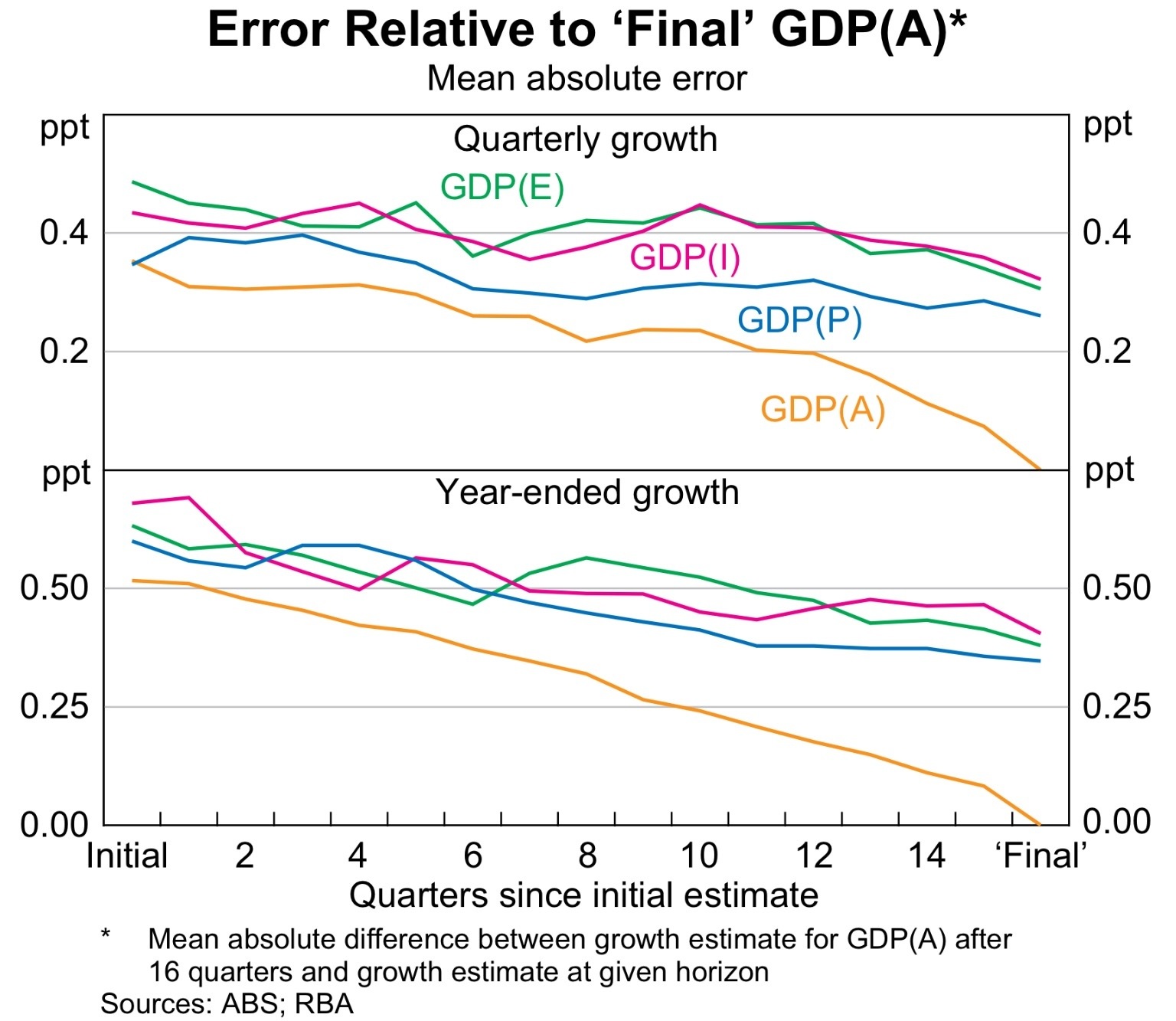
If pressed, it looks like GDP(P) is consistently the best single measure of output — particularly on a quarterly basis.
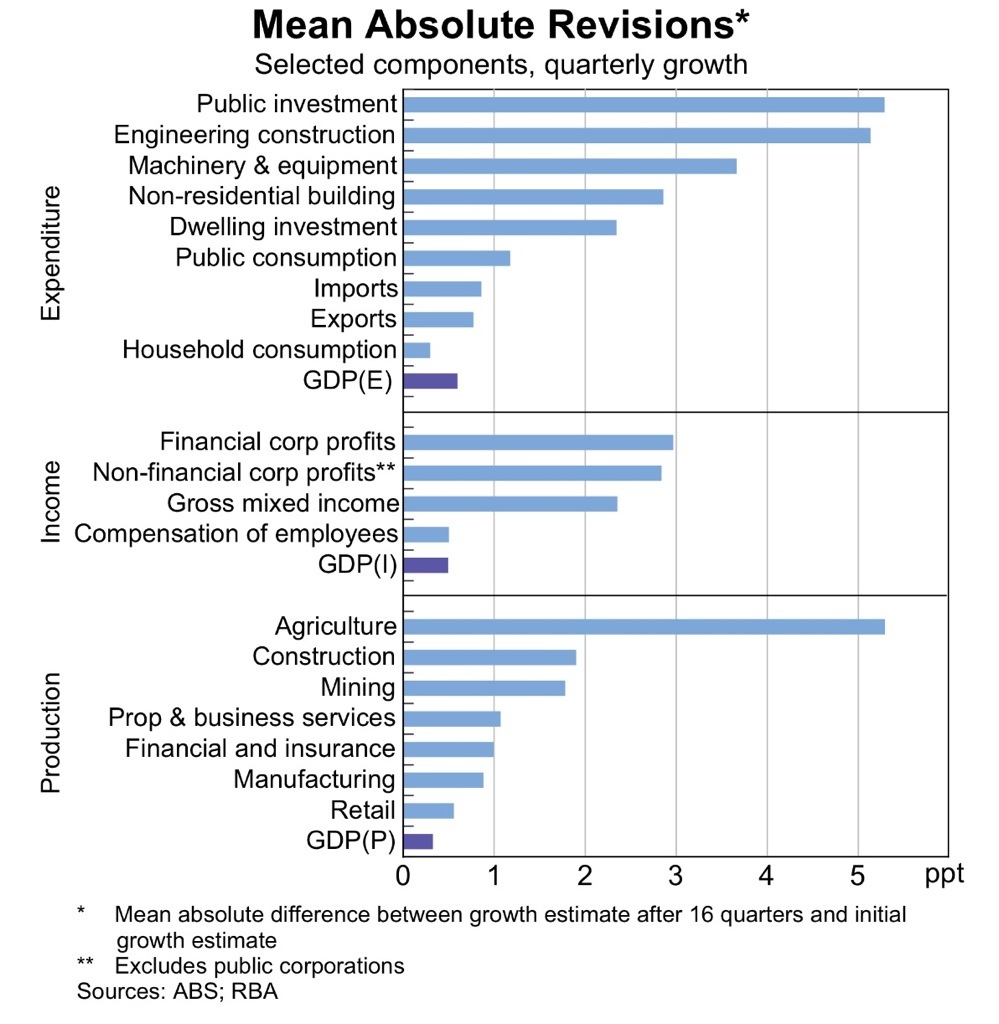
So what gets revised? Basically everything. Though the more volatile components tend to see the largest revisions — as you can see from the chart below.
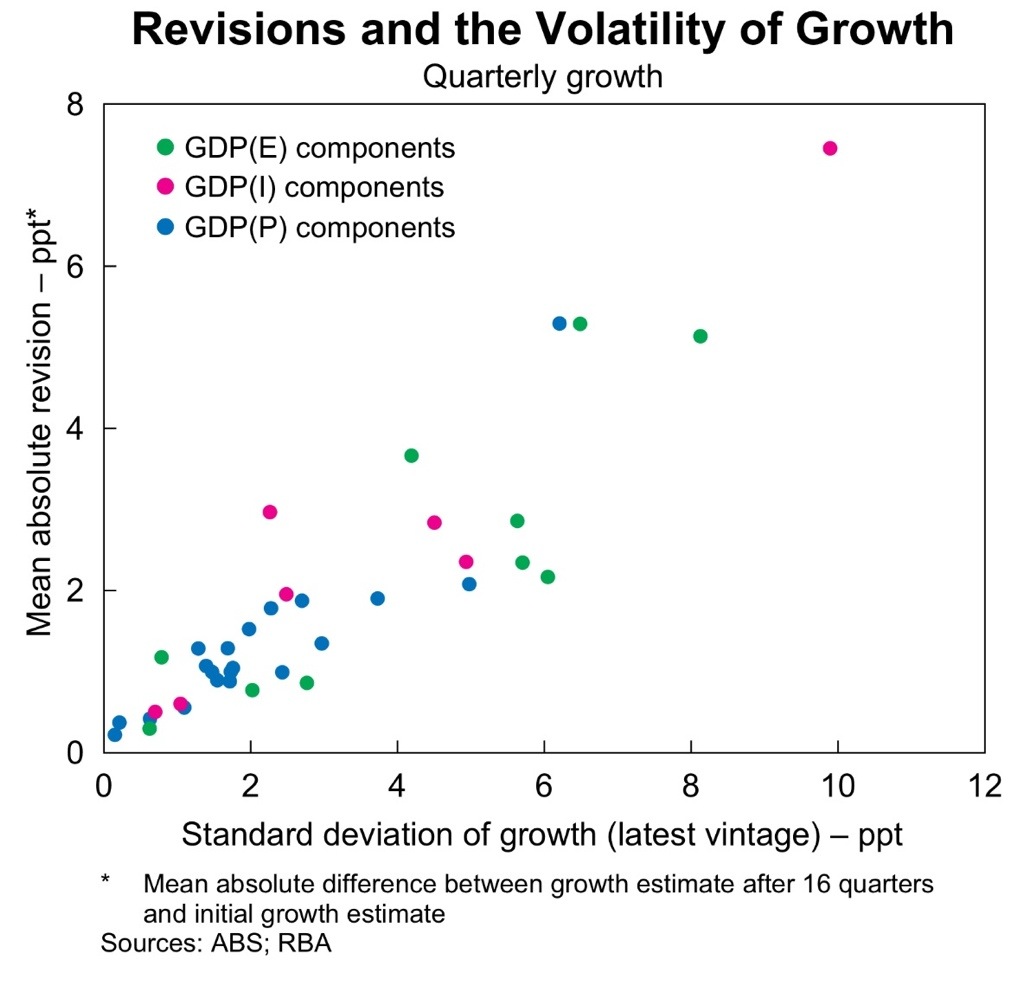
Weighting these by their economic importance, you can see the problem with the GDP(E) and GDP(I) measures – relative to GDP(P). Both GDP(E) and GDP(I) have components that tend to be very heavily revised (inventories and profits respectively).

This is not just a problem for Australia. Similar nations also tend to have persistent problems with the estimation of GDP.
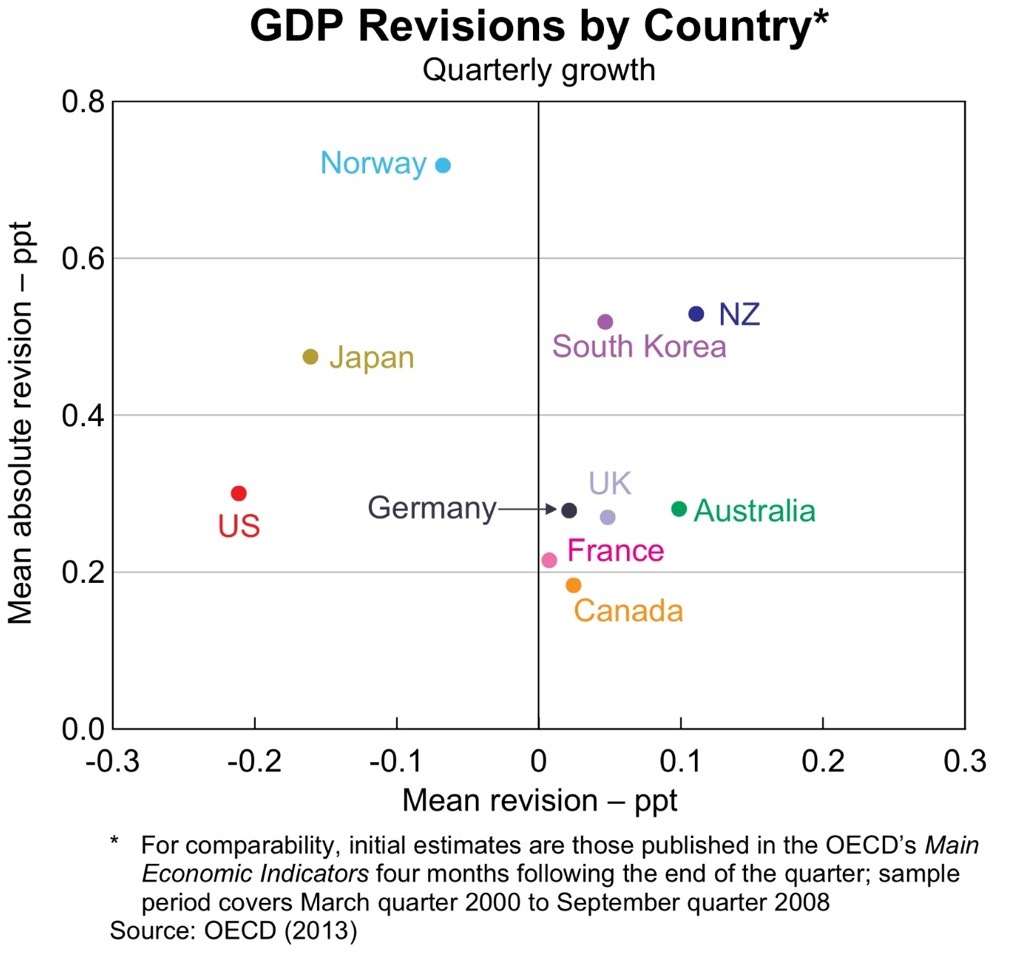
So what to do? The answer is to take averages of a large amount of data (so called factor models). At least in the US, research has shown that factor models defeat the real time / revision problem (see Bernanke and Bovin JME 2003)

Correct me I’m wrong RA but isn’t the fundamental problem with accurately forecasting GDP due to the way the statistics are aggregated. In simple terms many of the components of the National Accounting Framework are themselves forecasts or models and not actual measures. So in essence when forecasting for GDP you have to be able to allow for the inaccuracies of many of the forecasted GDP components.
On a second somewhat related question…do you think that the production of the National Accounts and GDP give a very false sense of accuracy?
Yep, that’s a part of the problem, for sure. The data is very partial when the first estimates are released. And yes, i do agree that the quarterly results get too much weight. The ABS tries to put the focus on the trends, but everyone loves the theatre of the QoQ SA estimates. Professionally, i use only factor models. I would never make or change a call based on any one release.
I se some-0ne lese has time to burn because of the rain
make that some-one else