
The post Q1 GDP recession debate has been both fun and informative (see my first and second posts, and Mark’s wonderful WA post), but what i really care about is monetary policy. With that in mind, i thought it useful to focus the conversation by looking at the relationship between inflation and various measures of growth.
I’ve chosen annual trimmed mean CPI inflation as my inflation measure, and have selected four measures of demand growth. I compare the annual pace inflation to the annual pace of growth, with growth lagged a year to fit the normal ‘sticky’ price narrative. Thus, the current period, which is the red dot on the charts, is Q1’13 CPI & Q1’12 growth.
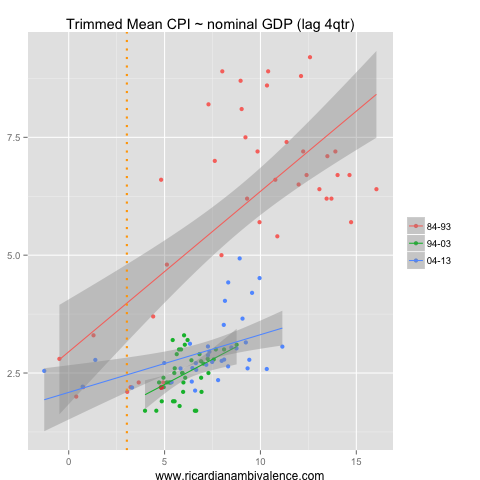
As inflation expectations have moved around over time, I broke the sample into decades using color. Finally i added an orange line to show where growth was in Q1’13 — so you can see what it means for future inflation.
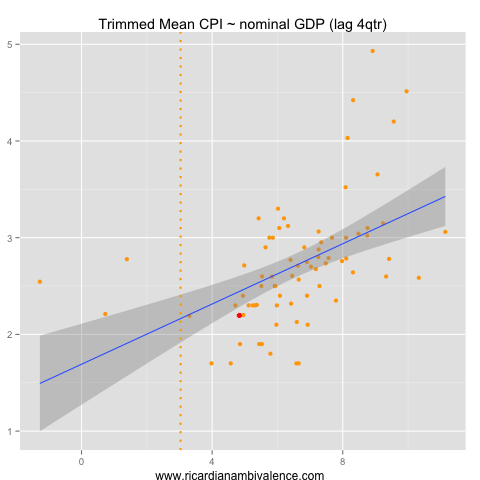
As I expected, the best fit was between prior nominal GDP growth and inflation. The relationship is robustly positive across all periods. We are currently below what would be expected given the historical fit, but in the realms of reasonable given the longer-run (pooled) relationship. Additionally, the present slow pace of nGDP growth suggests that inflation will remain low — or slow further (depending if you weight the change in the pace of growth or the pace more).
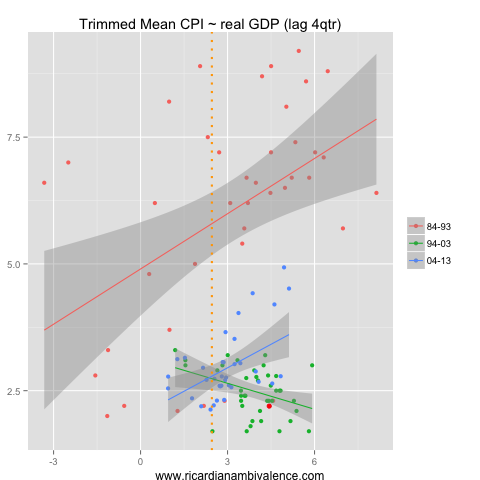
Prior nominal GDP easily out-performs real GDP as a predictor of inflation. Part of this is that we are capturing the serial correlation of inflation, but as a small open economy there are plenty of times when nominal GDP and CPI go in different directions, so I think that there’s more going on here. Note the disinflation of the 90s (which was partly about weak nominal growth) and the re-establishment of the prior growth-CPI relationship in the current cycle (as nominal growth picked up).
Note also that inflation is lower than you’d expect (as nGDP is weak), and that the pace of prior growth suggests easing inflation pressures.
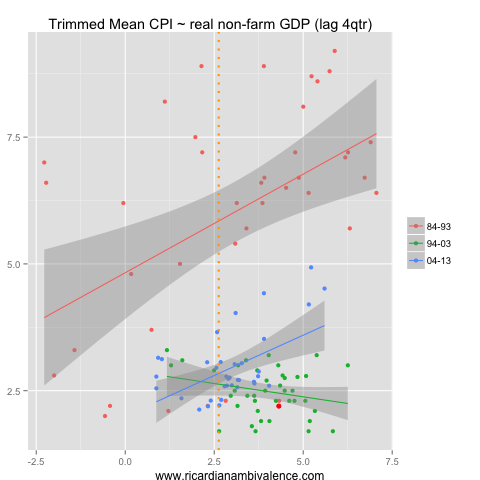
I prefer non-farm GDP to total GDP, as the rain adds a degree of randomness that is generally unhelpful when forecasting. Here we find a similar relationship to total (real) GDP. Again inflation is lower than you’d expect — and again, I think this is due to the weakness of nominal GDP.
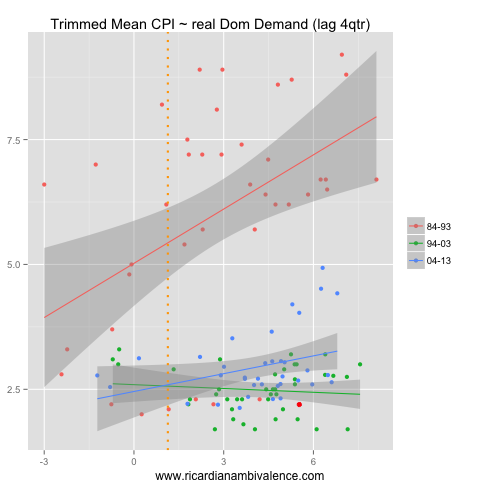
A narrow focus on the internal sector really only makes sense if you think that core inflation is basically a domestic event. If this were the case growth of domestic demand would be a better predictor of inflation: it isn’t …
The lesson I take from this exercise is that total GDP is more important than domestic demand (or GNE) when framing an inflation forecast — but that the state of the nominal economy is much more important than the pace of real demand growth.
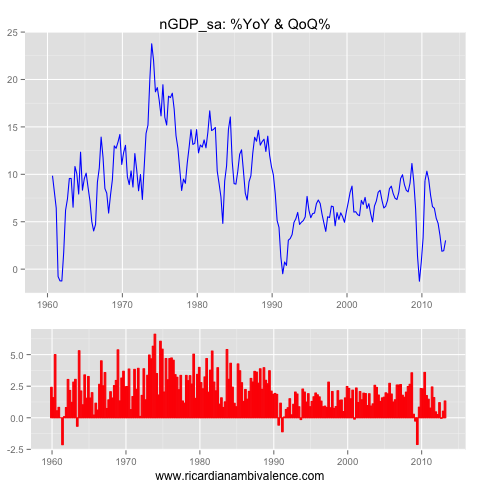
With that in mind, we ought to expect that core inflation will remain low — as nominal GDP growth remains mired at multi-decade lows. They seem likely to continue to fall as the terms of trade decline.

Thanks Ricardo, very interesting. It accords with my view that the sustainable rate of NGDP growth is about 5-6%, which we are of course well below.
How much predictive power does a simple ar(4) have? You gotta have a baseline!
well, you do and you don’t … correlation is informative in all cases, and there is information – particularly at turning points. all AR models tend to lag turning points, so knowing this stuff as well is handy.
i use VARs extensively for my professional work, but posting RMSE ratios and IRFs would make for a pretty narrow and boring blog :)
Very interesting graph from UBS (via Chris Weston) on the relationship between aging population and inflation: https://twitter.com/ChrisWeston_IG/status/343956878864297984/photo/1